Peruse 1.0 "The Birthday Release"
One day, about half a year or so ago, it came up in a discussion that while we in KDE have a lovely document viewer named Okular, we don't have something that is well suited to actually reading things, comic books in particular. So, a project was hatched to fix this. I've blogged about it before, and made a few tweets on the topic, but today is special. Today, 1.0 happens.
 (Alright, so it technically happened yesterday. But it's still special. At least, i think it's kind of special - it's called the birthday release for a reason, donchaknow ;) )
(Alright, so it technically happened yesterday. But it's still special. At least, i think it's kind of special - it's called the birthday release for a reason, donchaknow ;) )
Meet the Peruse comic book reader. This little application is based on KDE Frameworks 5, and is designed with the same principles as Plasma in mind: It should get out of your way and let you read your comics, comfortably. The user interface was designed and built using the Kirigami components, which the famous diving tool Subsurface also uses, and which is being developed by KDE's Plasma and VDG teams.
 So, what is next for Peruse? Well, apart from fixing bugs which have made their way into the release, and pushing various bits of code upstream that need to be upstream (such as the karchive rar support, which i discussed with the karchive maintainer last week; more on that in a different blog post), there are some big things that need doing (and some not so big things, obviously, as well).
So, what is next for Peruse? Well, apart from fixing bugs which have made their way into the release, and pushing various bits of code upstream that need to be upstream (such as the karchive rar support, which i discussed with the karchive maintainer last week; more on that in a different blog post), there are some big things that need doing (and some not so big things, obviously, as well).

 What if you have more ideas than those on the work board? Well, i would love to hear from you in that case! No idea is too crazy or far out. No, really, they're not - they may just not happen immediately ;) Anything that isn't small should likely not go on the bugtracker, though, but rather directly to me. If you want to catch me, either comment here, or get a hold of me on any number of various platforms, such as freenode irc (where i'm leinir and hang in a fair few channels), or twitter or, or, or... Basically, if you run into someone called leinir out there, it's fairly likely it'll be me.
What if you have more ideas than those on the work board? Well, i would love to hear from you in that case! No idea is too crazy or far out. No, really, they're not - they may just not happen immediately ;) Anything that isn't small should likely not go on the bugtracker, though, but rather directly to me. If you want to catch me, either comment here, or get a hold of me on any number of various platforms, such as freenode irc (where i'm leinir and hang in a fair few channels), or twitter or, or, or... Basically, if you run into someone called leinir out there, it's fairly likely it'll be me.
As with all such first releases, Peruse 1.0 is a bit rough around the edges and there are plenty of features that would be great to have in there - for example, there are no visual clues to suggest you can tap on the sides of the viewport to change pages when reading, and pdf and epub support feels very different to cbr support (and much less comfortable). If you come across any of those issues, please make sure to tell me about them - submit a ticket on the bugtracker for anything you run into that isn't right (though, please, and this goes for reporting on other products as well: check and make sure it hasn't been reported before. Help us help you :) )

The word of the day is: solstice - because this is the longest day of the year and that's pretty neat :)
Meet the Peruse comic book reader. This little application is based on KDE Frameworks 5, and is designed with the same principles as Plasma in mind: It should get out of your way and let you read your comics, comfortably. The user interface was designed and built using the Kirigami components, which the famous diving tool Subsurface also uses, and which is being developed by KDE's Plasma and VDG teams.
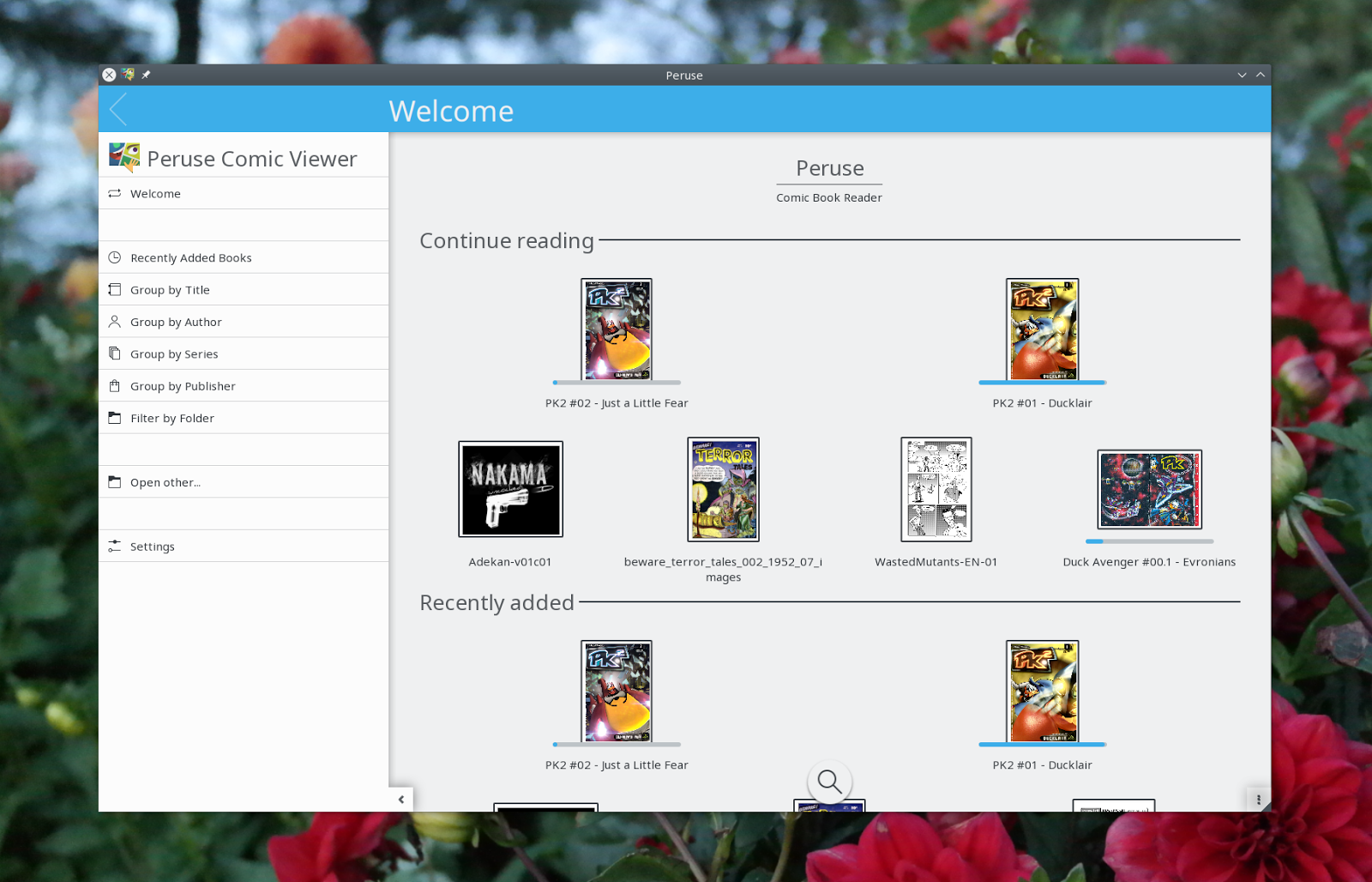 |
| The welcome page, where you can pick up reading where you left off last time, or navigate your way through your library in a range of different ways. Or, just open a file the way you might do it in other applications, if you've not got the thing you want in the library locations. |
 |
| The navigation sidebar you have available when reading your comic. In full screen (click the button in the middle), with the controls hidden (tap the comic view), you can show this by swiping in from the side, or with a hook gesture by swiping up from the bottom (because Windows eats the sideways swipes). |
 |
| When you reach either end of the comic and tap to try and continue past the end (by tapping the sides of the view), this drawer shows up to let you switch to other books in the same series. Because you don't want to be stuck on that cliffhanger ending, right? |
What Lies Ahead
 So, what is next for Peruse? Well, apart from fixing bugs which have made their way into the release, and pushing various bits of code upstream that need to be upstream (such as the karchive rar support, which i discussed with the karchive maintainer last week; more on that in a different blog post), there are some big things that need doing (and some not so big things, obviously, as well).
So, what is next for Peruse? Well, apart from fixing bugs which have made their way into the release, and pushing various bits of code upstream that need to be upstream (such as the karchive rar support, which i discussed with the karchive maintainer last week; more on that in a different blog post), there are some big things that need doing (and some not so big things, obviously, as well).
The things which are already planned can all be seen on the Peruse work board, but i feel that i should highlight the task entitled "Get Comics Online". Right now, the way you get comics is that you open your web browser and point it at some website where you happen to know comics can be found, such as Archive.org's Comic Books and Graphic Novels site, and then download things from there, which you then open Peruse to read. Now, that's all well and good, and that, basically, works. However, it just isn't good enough. The experience is jarring, and it really is just a bit silly when there are ways of making that much more pleasant.

Enter KNewStuff, a library created back in the olden days when the K in KDE still stood for Kool, and KDE was a bunch of software rather than a bunch of people who make software. The library was built to make it possible to get new stuff, specifically Get Hot New Stuff, into your applications, and to do so in a semi-social manner. Fast forward some ten, fifteen years, and we have a framework which, while it certainly functions (every tried getting new wallpapers using that little button in your desktop settings?), has a design which doesn't quite fit with how software tends to be built today. So, the next couple of months is going to be spent turning the functional framework into a modern, modular one which will work for a wider range of use cases and workflows. The work has already begun, and a plan was hatched at the Randa Meetings 2016 for how to proceed.
What does KNewStuff have to do with Archive.org, though? Well, honestly not a great deal. However, the plan for Peruse is to have a system which will allow you to have both KNewStuff capable sources (such as opendesktop.org, which things like Parley and KStars use in various forms), and non-ocs based ones, which will require more intervention in code form by yours truly. Archive.org's archive as linked above gives us a nice target for that: Lots of content to get, with licenses that means we can actually suggest people use it (read: it's not illegal content), and it is well structured, but not ocs based. So, having Peruse able to use those two types of sources means we should cover a fairly nice amount ground.
Ideas and Bugs
 What if you have more ideas than those on the work board? Well, i would love to hear from you in that case! No idea is too crazy or far out. No, really, they're not - they may just not happen immediately ;) Anything that isn't small should likely not go on the bugtracker, though, but rather directly to me. If you want to catch me, either comment here, or get a hold of me on any number of various platforms, such as freenode irc (where i'm leinir and hang in a fair few channels), or twitter or, or, or... Basically, if you run into someone called leinir out there, it's fairly likely it'll be me.
What if you have more ideas than those on the work board? Well, i would love to hear from you in that case! No idea is too crazy or far out. No, really, they're not - they may just not happen immediately ;) Anything that isn't small should likely not go on the bugtracker, though, but rather directly to me. If you want to catch me, either comment here, or get a hold of me on any number of various platforms, such as freenode irc (where i'm leinir and hang in a fair few channels), or twitter or, or, or... Basically, if you run into someone called leinir out there, it's fairly likely it'll be me.As with all such first releases, Peruse 1.0 is a bit rough around the edges and there are plenty of features that would be great to have in there - for example, there are no visual clues to suggest you can tap on the sides of the viewport to change pages when reading, and pdf and epub support feels very different to cbr support (and much less comfortable). If you come across any of those issues, please make sure to tell me about them - submit a ticket on the bugtracker for anything you run into that isn't right (though, please, and this goes for reporting on other products as well: check and make sure it hasn't been reported before. Help us help you :) )
Even More Awesomer!
On the note of helping us help you: The final sprint towards the release happened in part at the Randa Meetings 2016, and many other amazing things were achieved there. Not only that, but other sprints that KDE has through the year consistently yield both some heavy, intense coding sessions, and a lot of decisions which are just too difficult to make when you are not face to face with the people you need to talk with. So, if you want us to keep going and make more amazing stuff, click the banner below and donate what you can. If you can't donate, spread the word instead, help us raise enough to have the sprints we need to make KDE's software even better!The word of the day is: solstice - because this is the longest day of the year and that's pretty neat :)
posted by leinir at 6/22/2016 03:12:00 pm
![]()


9 Comments:
This comment has been removed by the author.
I don't know what qualifies as too large for https://bugs.kde.org, but I have two wishlist items:
1.) Manga (AKA right-to-left) page navigation
This doesn't mean you should display the last image in the archive first, just that the new page should come in from the left.
2.) Two-page view
Some comics have landscapes that span two pages. I would like to see the full picture.
Note that this depends on wishlist item 1 in that mangas would not be displayed correctly without accounting for it.
For example, a comic with the first page being [AB] and the second page being [CD] could be interpreted as [AB][CD] and displayed as [ABCD] without problem, but a manga with the first page being [BA] and the second page being [DC] should not be interpreted as [BA][DC] and displayed as [BADC], but rather interpreted as [DC][BA] and displayed as [DCBA].
Pseudo-edit: Bolded the pages for ease of viewing.
Nice project, thanks. I am going to compile and make some tests.
Kirigami, QML... humm... do you plan to create an Android version too? ;)
@Bodertz
Both of those are actually lovely and well defined, and would fit in very well as two separate issues on bugs.kde.org - and certainly they are both things that really should be included.
How, more precisely, to define when to use the manga style page navigation will need some thought, and likely user interaction... but storing the setting should be easy enough (basically, it could be done the same way the page count and current reading position is currently stored, but that's getting a bit technical ;) )
Thank you for the ideas, and thank you in advance for bko-ing them :D
@Filipe
Thank you very much, i look forward to hearing your findings! Hit me up on irc would likely be the best, you know where to find me :)
Yup, i will definitely get it on Android as well - the main stumbling block for Android is the use of kio-slaves in Peruse, but... that is a Framework, and it /needs/ to work on Android in at least a useful enough state that Peruse can use it (because others need the same types of functionality, which is really more a subset of what kio can really do), so that will be sorted ;)
Actually, for us down at the Equator, solstice is the shortest and coldest day for us.
This is a very nice project. Keep it up.
You are entirely correct, of course - i'm just up on the top of the globe (or bottom, kind of depends how you orientate your compass, i guess), and for me it's a long day, and i like that ;)
Thank you for the kind words! i fully intend to keep going :D
Hey,
What's up? I've got a HUGE collection of comics. Right now I like to use qComicBook, but Peruse looks pretty neat.
Some questions:
1. Would you be able to support 2 page span, but ignore first page? The biggest thing that leads to me using Okular over qComicbook with certain titles is that the first image is the front cover. If the program naively does a 2 page spread INCLUDING the title, it ends up uniting the wrong two pages. Okular does things correctly because it has a mode for this.
2. I noticed in the screenshots that you have support for publishers, descriptions, and other metadata. Where does this populate from? It seems like Peruse might be able to be the ComicRack of the Linux world. See, here's my current solution - to keep track of all that information in Tellico (KDE collection program). Then I use its ability to store URIs to then link to the PDF, EPUB, and CBZ version of the comics. So if I'm searching for, say, a comic written by Scott Snyder, I use tellico to search. Then I click on the URI to launch the file. (Unless I only have a physical copy. In which case, I've arranged the info in there to tell me what shortbox it's in)
@Eric
Monday morning and a cup of tea is what's up here ;) Thank you very much!
1) There is a bug report pertaining to this issue - https://bugs.kde.org/show_bug.cgi?id=364684 - so it certainly is something that will become possible. Building the heuristics for it is less obvious than one might imagine, but if you have some comics which need it... do send me an email :)
2) The metadata currently populates based on the simplest possible heuristic you can imagine (basically just splits up the file path based on the on-device location), but the idea is to make this much, much more capable. I must look at Tellico's database format, though, i'm sure you will not be the only person organising things using it... Perhaps a way to import metadata from there could be devised :)
The plan is to store the information in the cbz itself, using one or more of the existing formats, which while they aren't standards in the proper sense are implemented in an openly consumable format, so... in the spirit of cooperation and all that :)
Post a Comment
<< Home